ML记录-理论基础部分
前言:
记录自己的学习过程,方便后期回顾复习!
参考:吴恩达机器学习老版视频
1.线性回归
supervised learning algorithm 监督学习算法
regression 回归
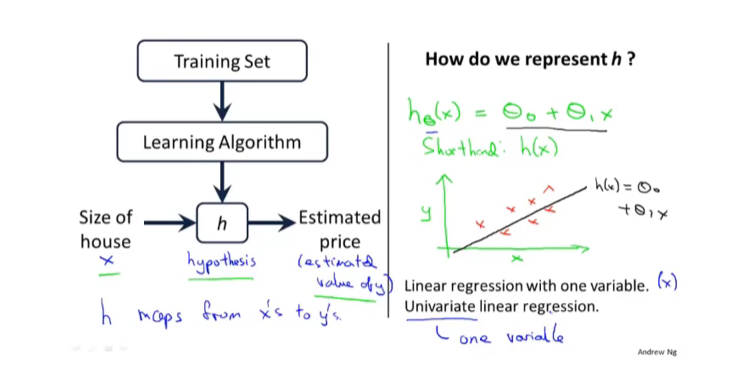
1.模型介绍
data set 数据集
m = number of training examples
x = input variable / features
y = output variable / target variable
(x,y) one training example
(x^i,y^i) i^th training example 【上标从1开始】
hypothesis 假设函数
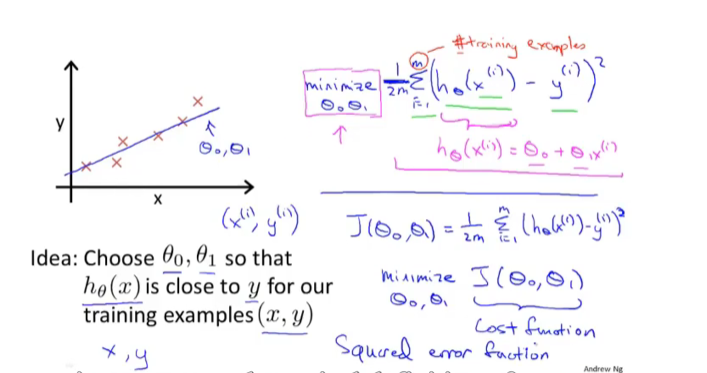
2.代价函数
theta_i 模型参数
cost function 代价函数
minimize 最小化
3.代价函数(一)
review:

this class:
侧重理解
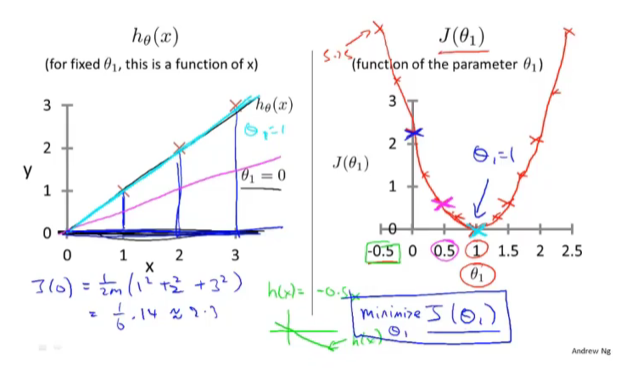
4.代价函数(二)
goal:
this class:
侧重理解二元的情况
5.梯度下降
gradient descent 梯度下降
assigment 赋值
learning rate 学习率 alpha
calculus 微积分
simultaneously update theta0 and theta1 同时更新θ0和θ1
start with some theta0 theta1 (say theta0=0, theta1=0)
class思路:


【以上:梯度下降的工作过程,和正确的更新方法】
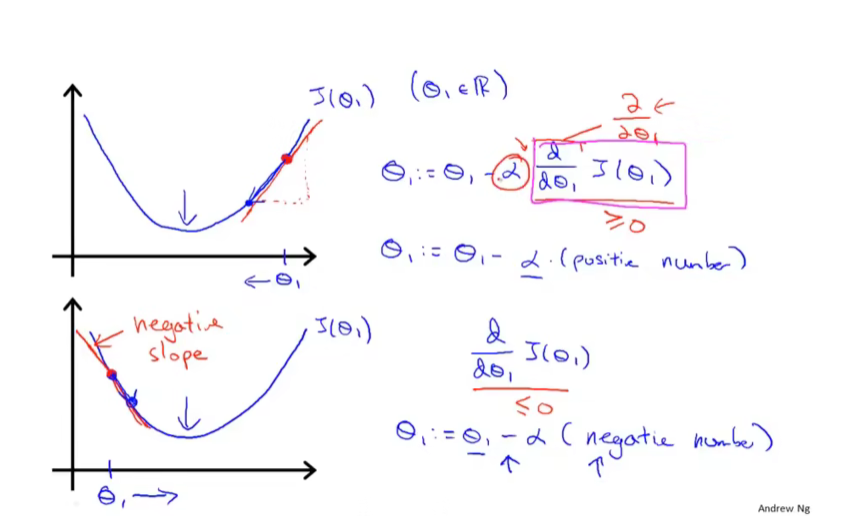
6.梯度下降知识总结

导数项的正负影响:
learning rate的大小影响:
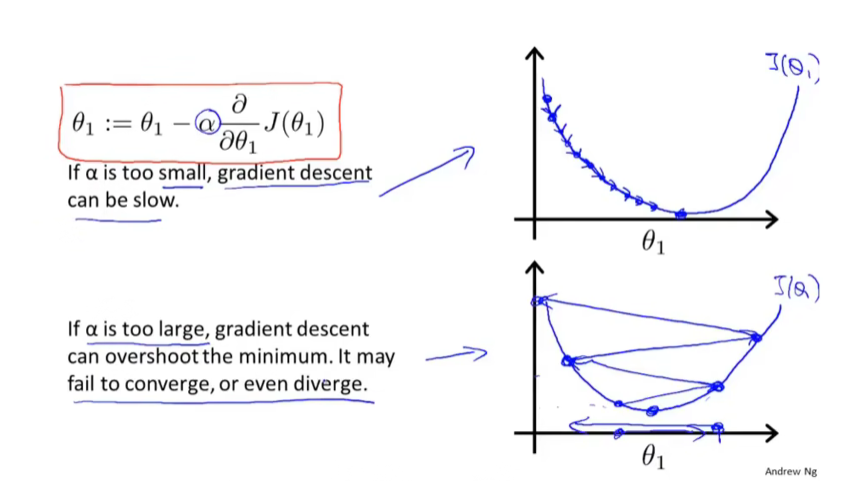
fixed learning rate导数项可以自动变化:
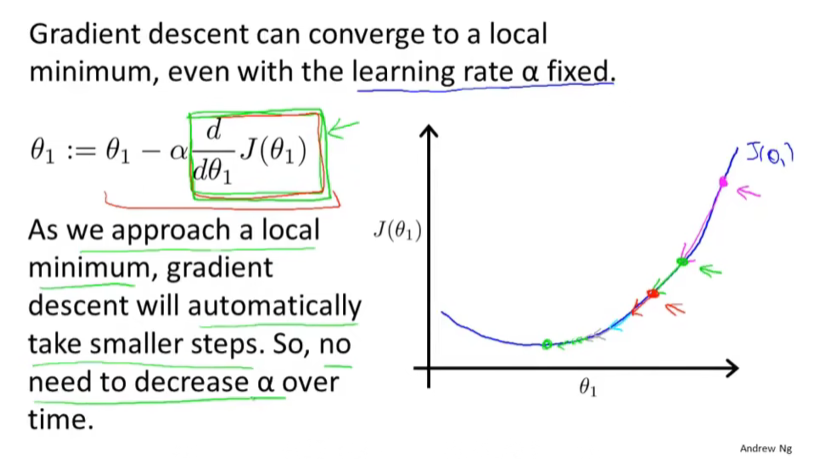
7.线性回归的梯度下降
convex function凸函数
bow-shaped functioin弓形函数
global optimum 全局最优
batch :each step of gradient descent uses all the training examples.

二元的梯度下降求导:
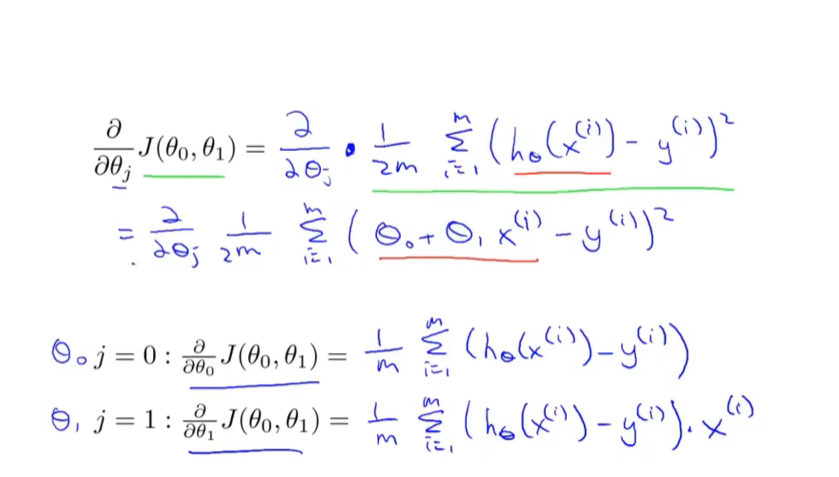
batch gradient descent:

2.多元情况(矩阵
1.多元假设函数
multiple variable / multiple features 多变量 多特征
four dimensional vector 四维向量
theta transpose θ转置
one matrix 一维矩阵
notation:
n = number of features
x^i = input features of i^th training example.
x^i_j = value of feature j in i^th training example.
多特征下的假设形式:

【x是n+1维、θ也是n+1维、x0=1】
multivariate linear regression. 多元线性回归
2.多元梯度下降法

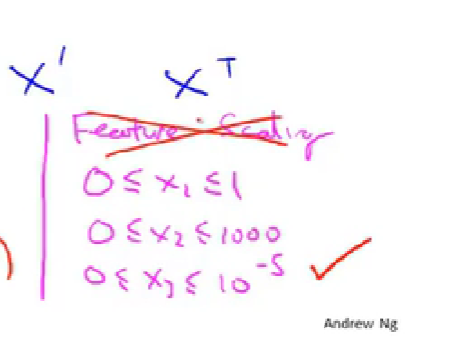
3.特征缩放-【帮助梯度下降更快的收敛】
feature scaling 特征缩放
fewer iterations 迭代次数少
converge more quickly 更快的收敛
skewed elliptical shape 歪斜的椭圆形
mean normalization 均值归一化
standard deviation 标准差
引例:
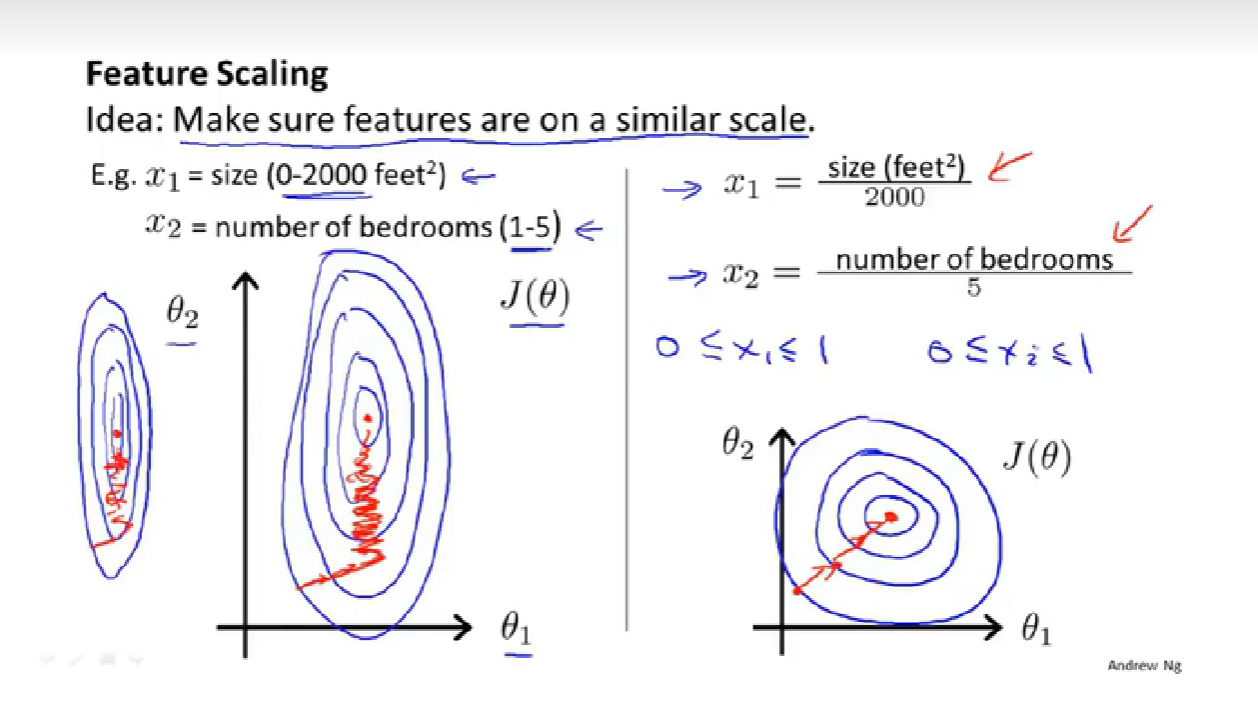
多少合适、多大可以接受:

均值归一化方法介绍:

4.学习率
automatic convergence test 自动收敛测试
small value epsilon ε【阈值】
图像可以提示你算法是否正常工作:【use smaller α】
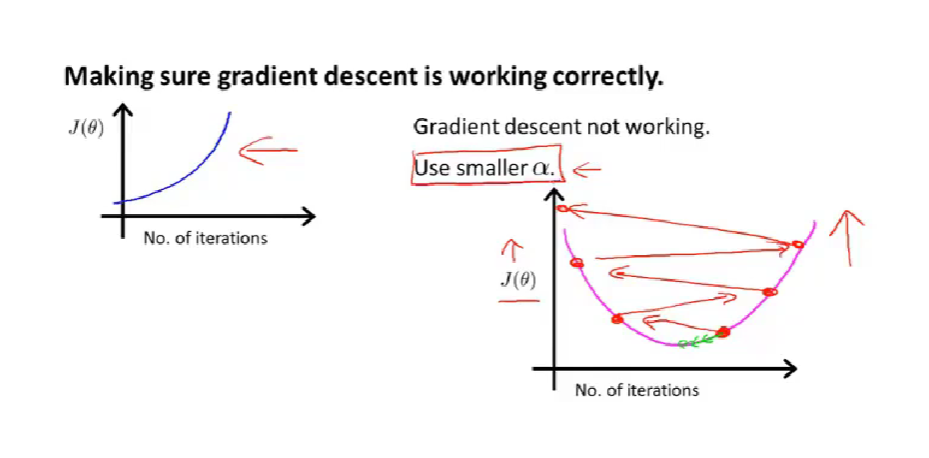
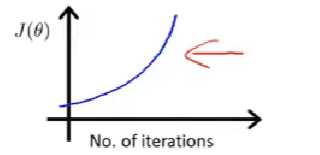
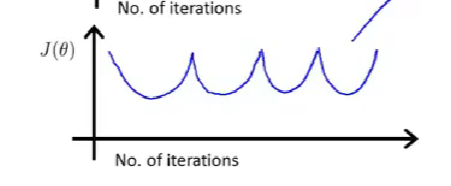
总结-取怎样的学习率合适:

5.特征和多项式回归
polynomial regression 多项式回归
to use the machinery of linear regression to fit very complicated, even very non-linear functions.
定义新的特征的例子:defining new features
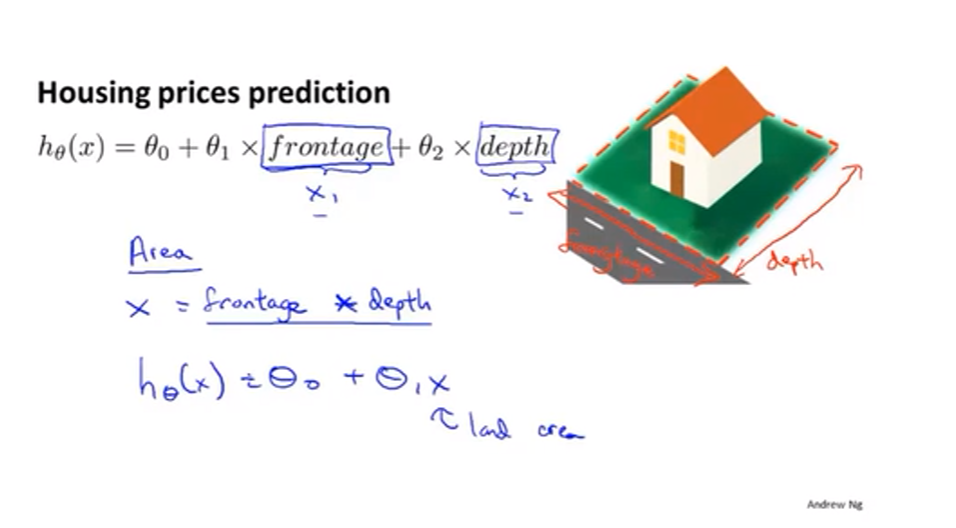
多项式回归:【feature scaling becomes increasingly important】
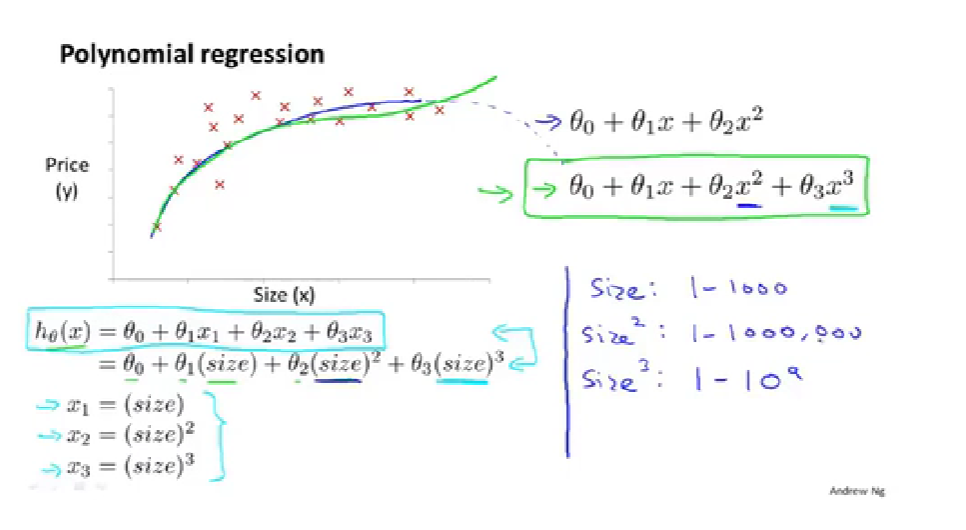
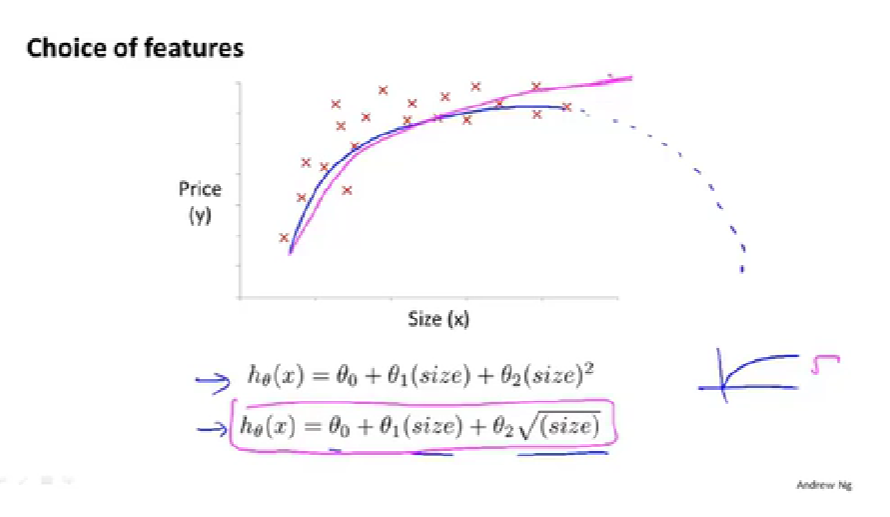
【如何决定使用什么特征很困难,之后的课程会探讨算法自动选择要使用的特征,来决定是二次还是三次等等】
6.正规方程(区别于迭代法
normal equation 正规方程
design matrix 设计矩阵
例子:
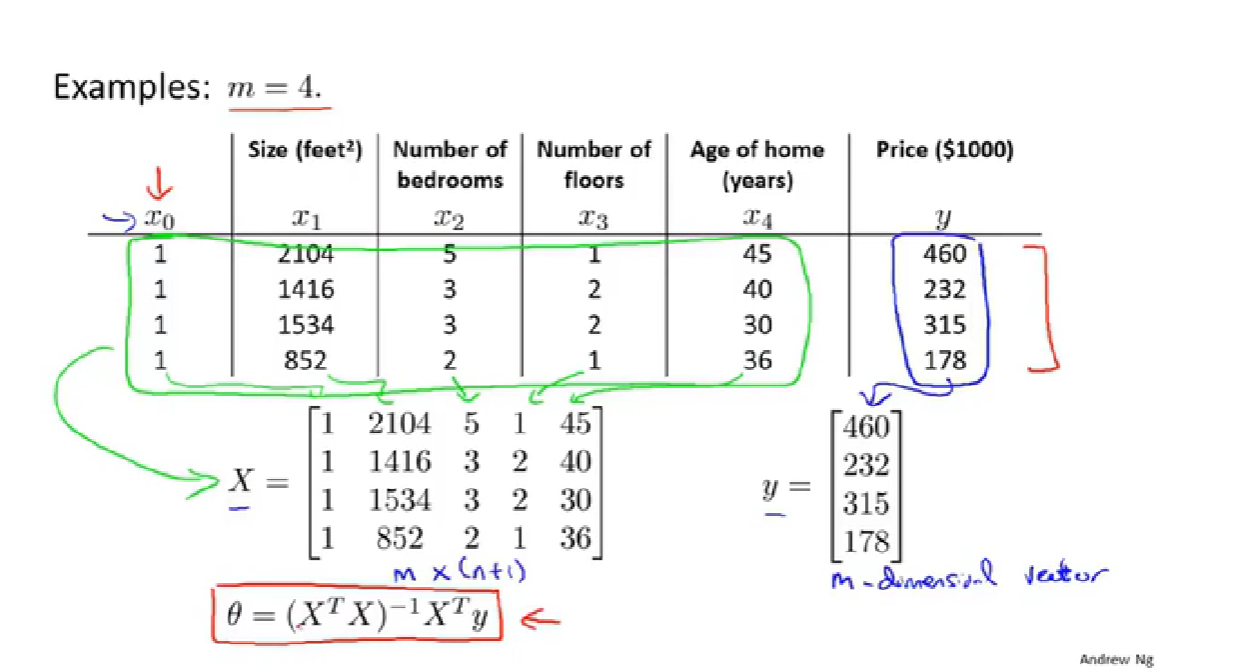
构建设计矩阵:【不难】
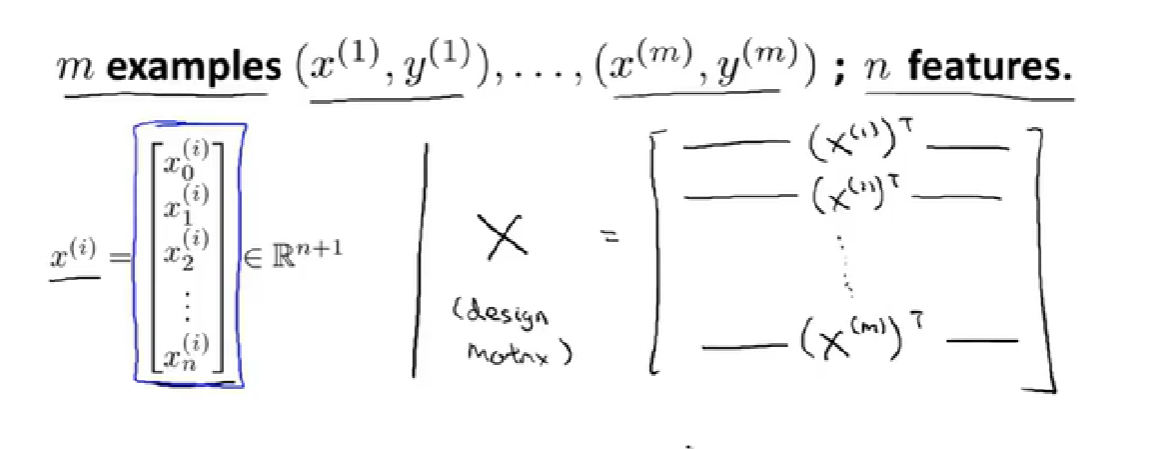
正规方程法:【不需要特征缩放,n小时代价小】
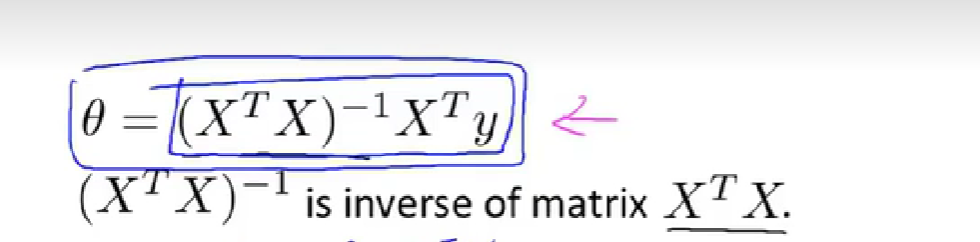
正规方程和梯度下降的优缺点,何时使用正规方程:【当n很大时梯度下降】【求n维的矩阵的逆矩阵的代价是三次方】【正规方程适用于线性回归】

7.正规方程在矩阵不可以下的解决办法【选学】
normal equation and non-invertibility 正规方程以及不可逆性
non-invertiable (singular/degenerate) 奇异/退化矩阵
pinv 伪逆 【即使矩阵没有逆矩阵也能正常工作】
inv 逆
2.什么情况下会出现矩阵不可逆的情况:
【存在特征线性相关的多余特征】【样本数量小于特征数量】

3.logistic回归-分类
1.分类
discrete value 离散值
logistic regression logistic回归
binary classification problem 二元分类
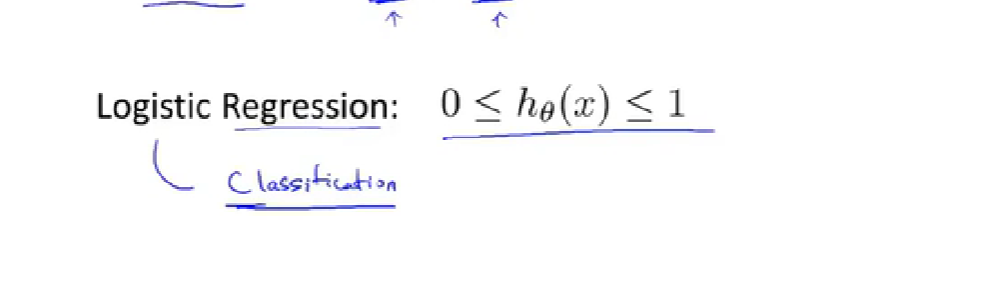
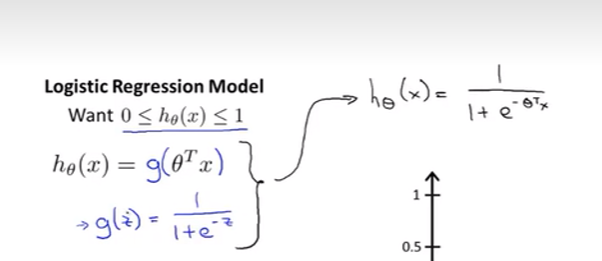
2.假设陈述
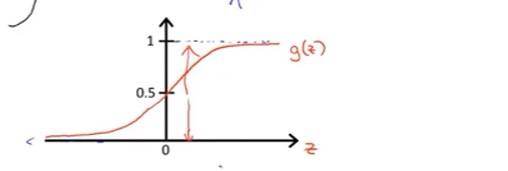
sigmoid function / logistic function == function g
假设函数:
3.简化代价函数于梯度下降


正则化【应对过拟合
regularization 正则化
regularization parameter 正则化参数λ lambda
【参数越小函数越平滑】
正则化:【用来缩小每个参数的值】【从1开始到n,没有0】
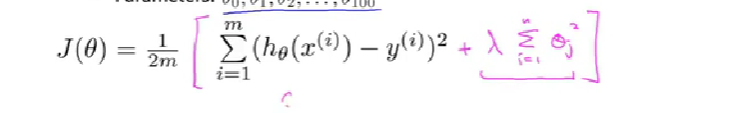
【后面会有方法自动选择λ】
线性回归的正则化【两种方法更新
梯度下降更新的改变:【和直观理解】

【解释:θ0没有惩罚,单独拉出来。其他的求导化简以后就是最后一个式子,就是每次θ都乘以一个小于1的数】
正规方程方法的改变:【同时解决了不可逆的问题,一定可逆了就】

logistic回归的正则化
梯度下降法的更新:

【和线性回归的几乎一样,假设函数不一样】
高阶的方法的更新:略。
4.神经网络
1.模型展示1
neural networks 神经网络
neurons 神经元
dendrites 树突
axon 轴突
a neuron is a computational unit.
spikes 动作电位
logistic unit 逻辑单元【神经元模拟成一个逻辑单元】
bias unit / bias neuron 偏置单元/偏置神经元【总是为零】
sigmoid(logistic) activation function 激活函数
weights of model == 权重【参数】
first layer == input layer 第一层叫做输入层
final layer == output layer 最后一层叫做输出层
hidden layer 中间的叫做隐藏层
激活项 == 一个具体神经元计算并输出的值
matrix of weights 权重矩阵
模型展示/假设函数:数学定义

2.模型展示2
forward propagation 向前传播
vectorized implementation 向量化实现
向前传播【向量化】: